Optimization of AI Performance of SoCs for AD/ADAS
In recent years, advances in artificial intelligence (AI) technology based on deep learning have led to an increasing number of situations where AI is directly useful in our daily lives, such as improving the accuracy of automatic translation and making recommendations that match consumers' preferences. One example is automated driving (AD) and advanced driver assistance (ADAS) in automobiles.
Since the processing of recent AI models represented by deep neural networks (DNNs) requires large-scale parallel operations, GPUs capable of general-purpose parallel operations are often used for development on PCs. On the other hand, SoCs for AD and ADAS are increasingly equipped with dedicated circuits (hereinafter referred to as "accelerators") that realize DNN processing with low power consumption and high performance. However, it is generally not easy to confirm at an early stage of SoC development whether the on-chip accelerator can deliver sufficient performance for the DNN that one wishes to use. TOPS (Tera Operations Per Second) values, which represent the maximum arithmetic performance of the accelerator design, and TOPS/W values, which are calculated by dividing the above by the power consumption during operation, are often used as indicators for performance comparisons. But since accelerators are designed specifically to perform specific processing at high speed (*1), even if the TOPS values are sufficient, the performance of the accelerator may not be sufficient due to the existence of operations that cannot be processed efficiently or insufficient data transfer bandwidth. In addition, the power consumption of the overall SoC may exceed the acceptable range due to an increase in accelerator power.
(*1) Dedicated design: While it is possible to use a general-purpose GPU as an accelerator, hardware design focused on specific processing can achieve higher processing performance with less circuit size and power consumption. For example, the accelerators in Renesas' automotive SoCs, R-Car V3H, R-Car V3M, and R-Car V4H, have a structure suitable for processing convolutional neural networks (CNN), which use convolutional operations for feature extraction among DNNs.
As SoC development progresses, the degree of difficulty in making design changes due to insufficient performance or excessive power consumption generally increases, and the impact on the SoC development schedule and development cost also increases. For this reason, it is very important in the development of SoCs for automotive AI devices to confirm at an early stage of SoC development whether the accelerator to be installed can deliver sufficient performance for the DNN that the customer product wants to use and whether the power consumption is within an acceptable range.
The general flow of AI development for AD/ADAS
Before going into an explanation of our approach to the above issues, we will briefly explain the flow of AI development in AD/ADAS. Figure 1 below shows an example of the flow of AI development for AD/ADAS, focusing on software and including part of SoC development.
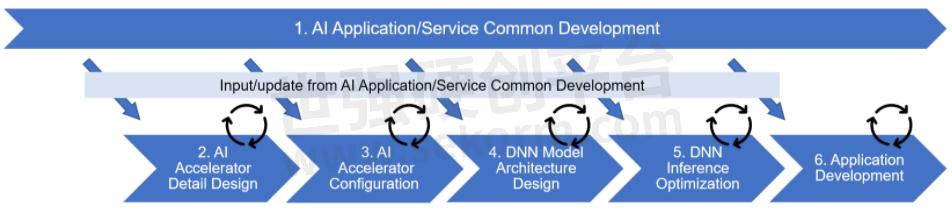
Figure 1: Example of AI development flow in AD/ADAS
Figure 1 divides the entire development into six phases, with phases 2 and 3 being SoC circuit design and the other phases 1 and 4-6 being software development. The outline of work in each phase is as follows.
In Phase 1, AI Application/Service Common Development, we continuously develop AI applications and services for AD/ADAS using PC and cloud environments in response to market needs and technology trends.
In AI Accelerator Detail Design in phase 2, we design the components that make up the accelerator hardware, such as the arithmetic unit, built-in memory, and data transfer unit.
In AI Accelerator Configuration Design in Phase 3, the components designed in Phase 2 are integrated to optimize the trade-offs among area, power, and performance. This integration process enables the determination of the accelerator configuration within the System-on-Chip (SoC), aligning with the desired design objectives.
In DNN Model Architecture Design in phase 4, the accelerator configuration determined in phase 3 is used to optimize the network structure of each DNN which is expected to be used in the customer's product.
In DNN Inference Optimization in phase 5, code generation for accelerators, detailed evaluation of accuracy and processing time, and optimization of code and model data are performed for each network whose structure has been optimized in phase 4.
In the final application development stage in phase 6, the AI processing component, which has been optimized in step 5 through code and model data enhancements, is integrated into an application that performs specific tasks such as automated driving. This involves implementing and evaluating the application side, ensuring that the AI processing functions effectively within the overall system.
Renesas' Approach
In the flow of AI development in AD/ADAS described in the previous section, it is necessary to determine whether the accelerator equipped with the DNN that you want to use can provide sufficient performance in the AI Accelerator Configuration phase, which basically determines the configuration of the accelerator. The following is a brief overview of the AI Accelerator Configuration phase.
In the past, judgments at this stage were made by estimating from the results of benchmarks conducted using existing SoCs with similar accelerators. However, the estimation accuracy is limited because benchmark results cannot be obtained for areas where specifications differ from those of existing SoCs due to the addition or modification of functions, it was impossible to make judgments about whether the design goals could be achieved or not, based on accurate estimation.
Renesas has effectively addressed this issue by employing the PPA Estimator (Performance, Power, Area) instead of relying solely on benchmarking with existing System-on-Chips (SoCs). The PPA Estimator utilizes a calculation model that considers the design specifics of each accelerator component, enabling the estimation of performance and power consumption before finalizing the accelerator configuration.
To evaluate different accelerator configurations, a list of potential configurations is generated, each comprising various adjustable parameters like the number of processing units and internal memory capacity. One configuration is selected at a time and inputted into the PPA Estimator, which calculates the corresponding time required for processing and power consumption. This iterative process is repeated for the desired number of Deep Neural Networks (DNNs) and accelerator configurations, generating data that facilitates the identification of the optimal accelerator configuration.
This approach not only enables the assessment of whether a particular accelerator configuration and DNN combination yield adequate performance but also allows for the collection of a broad range of data. Ultimately, this data-driven analysis aids in selecting the most optimal accelerator configuration from the available options.
To enhance the effectiveness of the AI Accelerator Configuration phase (phase 3), Renesas implements concurrent improvements on the software side. This is achieved by leveraging the insights gained from the execution results of the PPA Estimator and applying them as feedback to the network model of the target Deep Neural Network (DNN). This process involves performing hardware-software co-design (co-design) to optimize the overall system performance. Figure 2 below shows the workflow of the AI Accelerator Configuration phase.
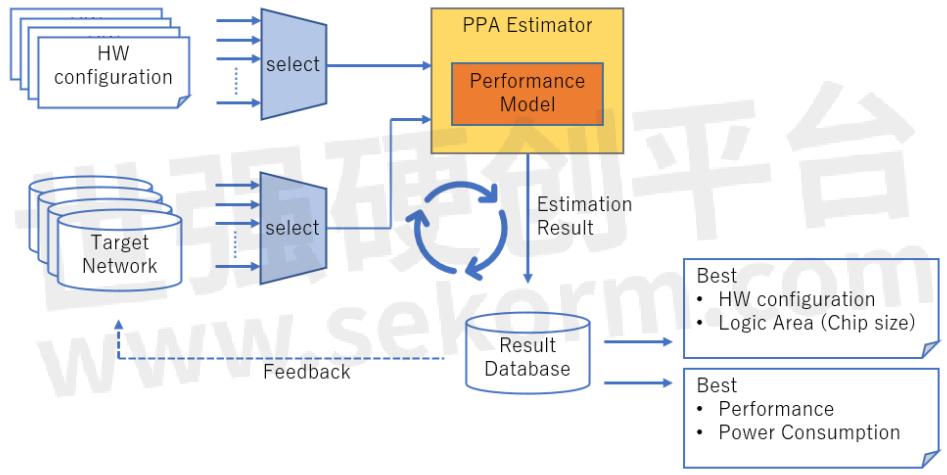
Figure 2: Workflow of AI Accelerator Configuration
Renesas has started applying PPA Estimator to the development of some SoCs for AD/ADAS with accelerators for AI processing from 2023 and plans to expand the scope of application gradually. Renesas will use PPA Estimator to search for optimal configurations and develop in-vehicle AI accelerators with high performance and low power consumption.
- +1 Like
- Add to Favorites
Recommend
- Renesas Introduces Complete Power and Functional Safety Solution for R-Car V3H ADAS Camera Systems
- Renesas Developed R-Car V3H and V3M ETS Portal, Which Are “Easy to Start“ for ADAS
- Renesas and LUPA Develop Open Platform Turnkey Solution with R-Car SoCs
- Renesas New R-Car SDK is an Easy-to Start & Easy-to-Use Development Framework for the R-Car V Series SoCs
- Renesas Developed Autonomy Platform for ADAS and Automated Driving
- Renesas Shifts Mobility System Development into High Gear with Its New Online Market Place for R-Car SoC
- Renesas Accelerates ADAS and AD Development with Best-in-Class R-Car V3U ASIL D System on Chip
- Renesas Collaborates with Microsoft to Accelerate Connected Vehicle Development
This document is provided by Sekorm Platform for VIP exclusive service. The copyright is owned by Sekorm. Without authorization, any medias, websites or individual are not allowed to reprint. When authorizing the reprint, the link of www.sekorm.com must be indicated.
Integrated Circuits












































































































































































































































































































































Discrete Components



























































































































































































Connectors & Structural Components





























































Assembly UnitModules & Accessories
















































































































Power Supplies & Power Modules






Electronic Materials







































































Instrumentation & Test Kit










































Electrical Tools & Materials





Mechatronics










Processing & Customization






















































